


Son fundamentales para muchos algoritmos de procesamiento de lenguaje natural (NLP), recomendación y búsqueda. Si alguna vez has utilizado sistemas como motores de recomendación, asistentes de voz, traductores de idiomas, entonces has interactuado con sistemas basados en incrustaciones de vectores.
Los algoritmos de machine learning ML, que brinda a las computadoras la capacidad de interpretar, manipular y comprender el lenguaje humano, en realidad necesitan números para trabajar, como la mayoría de los algoritmos de software. A veces tenemos un conjunto de datos con columnas de valores numéricos o valores que se pueden traducir a ellos (ordinales, categóricos, etc.). Otras veces nos encontramos con algo más abstracto como un documento completo de texto. Creamos incrustaciones de vectores, que son solo listas de números, para datos como este para realizar varias operaciones con ellos. Un párrafo completo de texto o cualquier otro objeto se puede reducir a un vector. Incluso los datos numéricos se pueden convertir en vectores para facilitar las operaciones.
Veamos brevemente cómo funcionan las incrustaciones de vectores:

- Corpus de entrenamiento: Se necesita un corpus de texto grande y diverso para entrenar los vectores. Esto puede ser una colección de documentos, libros, artículos de noticias o incluso todo Internet.
- Tokenización: El corpus de entrenamiento se divide en unidades más pequeñas, como palabras o frases. Cada unidad se denomina token y se representa como una secuencia de caracteres.
- Construcción de vocabulario: Se crea un vocabulario a partir de los tokens únicos presentes en el corpus de entrenamiento. Cada palabra del vocabulario se asigna a un índice único.
- Ventanas de contexto: Se define una ventana de contexto para cada palabra en el corpus de entrenamiento. La ventana de contexto es una cantidad fija de palabras que rodea a la palabra objetivo. Por ejemplo, si la ventana de contexto es de tamaño 5, se considerarían las 2 palabras anteriores y las 2 palabras siguientes a la palabra objetivo.
- Modelos de aprendizaje: Hay diferentes algoritmos y modelos utilizados para entrenar las incrustaciones de vectores. Uno de los métodos más comunes es el modelo de lenguaje de Word2Vec, que utiliza una red neuronal para predecir las palabras de contexto dadas las palabras objetivo. Otro método popular es GLoVE, que utiliza información estadística basada en la co-ocurrencia de palabras en un corpus.
- Aprendizaje y optimización: Durante el entrenamiento, los modelos ajustan los vectores de palabras para maximizar la probabilidad de predecir las palabras de contexto correctamente. Esto se logra mediante la minimización de una función de pérdida, como la entropía cruzada.
- Obtención de vectores: Después del entrenamiento, cada palabra del vocabulario se representa como un vector numérico de dimensiones fijas. Estos vectores capturan información sobre las similitudes y relaciones entre palabras según el contexto en el que aparecen.
Pero hay algo especial en los vectores que los hace tan útiles. Esta representación hace posible traducir la similitud semántica percibida por los humanos a la proximidad en un espacio vectorial.
En otras palabras, cuando representamos objetos y conceptos del mundo real como imágenes, grabaciones de audio, artículos de noticias, perfiles de usuarios, patrones climáticos y puntos de vista políticos como incrustaciones de vectores, la similitud semántica de estos objetos y conceptos se puede cuantificar por qué tan cerca son entre sí como puntos en espacios vectoriales. Las representaciones de incrustación de vectores son, por lo tanto, adecuadas para tareas comunes de aprendizaje automático, como agrupación, recomendación y clasificación.
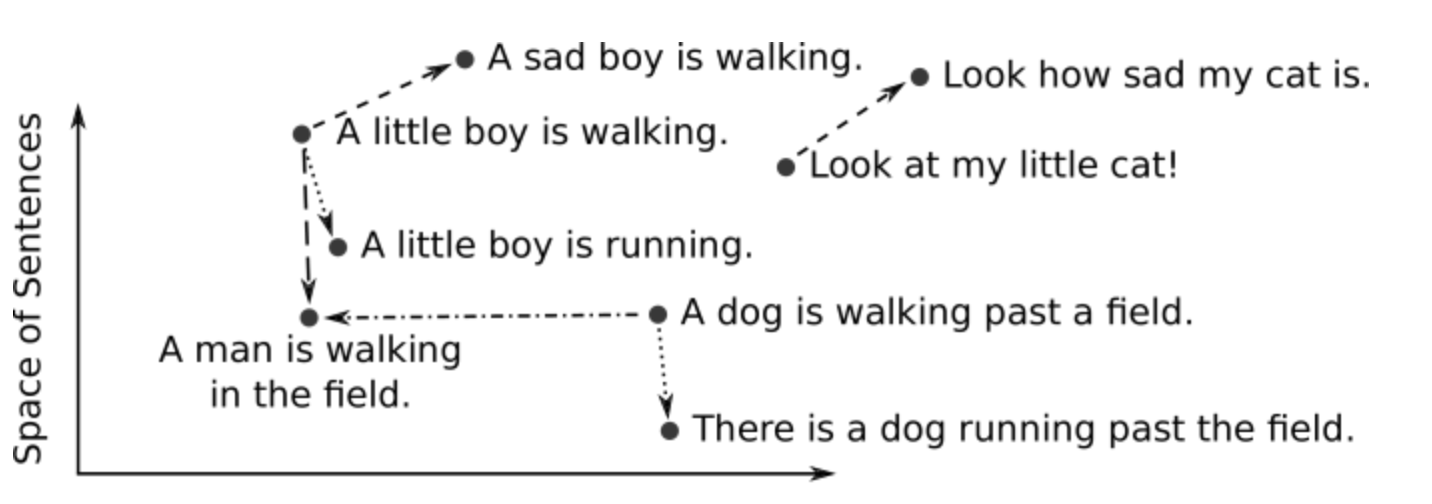
Una vez que se han entrenado las incrustaciones de vectores, se pueden utilizar en diversas tareas de procesamiento del lenguaje natural, como la clasificación de texto, la traducción automática, la agrupación de documentos y la recuperación de información, entre otros.
Es importante destacar que las incrustaciones de vectores son aprendidas de manera supervisada a partir de grandes cantidades de texto y, por lo tanto, reflejan las características del corpus de entrenamiento. Esto significa que las incrustaciones pueden capturar sesgos inherentes al texto de entrenamiento y es fundamental tener en cuenta este aspecto al aplicarlas en aplicaciones del mundo real.
Creación de incrustaciones de vectores
Una forma de crear incrustaciones de vectores es diseñar los valores de los vectores utilizando el conocimiento del dominio. Esto se conoce como ingeniería de características. Por ejemplo, en imágenes médicas, utilizamos la experiencia médica para cuantificar un conjunto de características como forma, color y regiones en una imagen que captura la semántica. Sin embargo, la ingeniería de incrustaciones de vectores requiere conocimiento del dominio y es demasiado costosa para escalar.
En lugar de incrustaciones de vectores de ingeniería, a menudo entrenamos modelos para traducir objetos a vectores. Una red neuronal profunda es una herramienta común para entrenar tales modelos. Las incrustaciones resultantes suelen ser de alta dimensión (hasta dos mil dimensiones) y densas (todos los valores son distintos de cero). Para datos de texto, modelos como Word2Vec, GLoVE y BERT transforman palabras, oraciones o párrafos en incrustaciones de vectores.
Las imágenes se pueden incrustar utilizando modelos como las redes neuronales convolucionales (CNN). Los ejemplos de CNN incluyen VGG e Inception. Las grabaciones de audio se pueden transformar en vectores usando transformaciones de incrustación de imágenes sobre la representación visual de las frecuencias de audio (por ejemplo, usando su espectrograma).
Ejemplo de incrustación de imágenes
Considera el siguiente ejemplo, en el que las imágenes sin procesar se representan como píxeles en escala de grises. Esto es equivalente a una matriz (o tabla) de valores enteros en el rango de 0 a 255 . Donde el valor 0 corresponde a un color negro y 255 a un color blanco. La siguiente imagen muestra una imagen en escala de grises y su matriz correspondiente.

La subimagen de la izquierda representa los píxeles en escala de grises, la subimagen del medio contiene los valores de escala de grises de los píxeles y la subimagen más a la derecha define la matriz. Observe que los valores de la matriz definen un vector incrustado en el que su primera coordenada es la celda superior izquierda de la matriz, luego va de izquierda a derecha hasta la última coordenada que corresponde a la celda inferior derecha de la matriz.
Estas incrustaciones son excelentes para mantener la información semántica de la vecindad de un píxel en una imagen. Sin embargo, son muy sensibles a transformaciones como cambios, escalado, recorte y otras operaciones de manipulación de imágenes.
La red neuronal convolucional (CNN o ConvNet) es una clase de arquitecturas de aprendizaje profundo que generalmente se aplican a datos visuales que transforman imágenes en incrustaciones.
Las CNN procesan la entrada a través de pequeñas subentradas locales jerárquicas que se denominan campos receptivos. Cada neurona en cada capa de la red procesa un campo receptivo específico de la capa anterior. Cada capa aplica una convolución en el campo receptivo o reduce el tamaño de entrada, lo que se denomina submuestreo.
La siguiente imagen muestra una estructura típica de CNN. Observe los campos receptivos, representados como subcuadrados en cada capa, que sirven como entrada a una sola neurona dentro de la capa anterior. Observe también que las operaciones de submuestreo reducen el tamaño de la capa, mientras que las operaciones de convolución amplían el tamaño de la capa. La incrustación de vectores resultante se recibe a través de una capa completamente conectada.
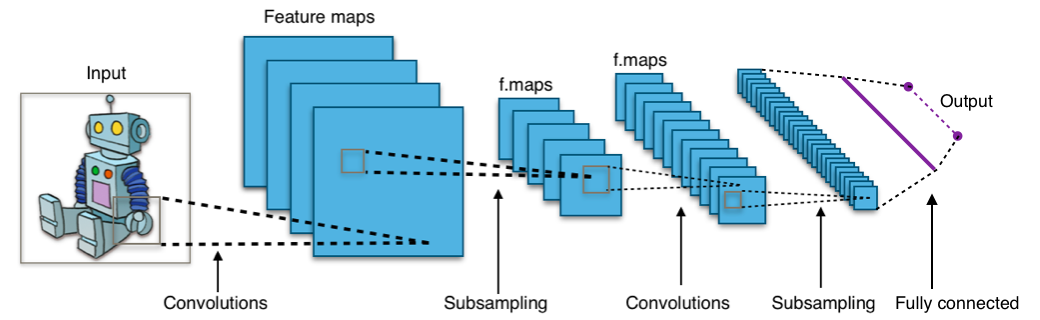
Aprender los pesos de la red (es decir, el modelo integrado) requiere un gran conjunto de imágenes etiquetadas. Los pesos se están optimizando de manera que las imágenes con las mismas etiquetas se incrustan más cerca en comparación con las imágenes con diferentes etiquetas. Una vez que aprendemos el modelo de incrustación de CNN, podemos transformar las imágenes en vectores y almacenarlas con un índice K-Nearest-Neighbor. Ahora, dada una nueva imagen no vista, podemos transformarla con el modelo CNN, recuperar sus k vectores más similares y, por lo tanto, las imágenes similares correspondientes.
Aunque usamos imágenes y CNN como ejemplos, las incrustaciones de vectores se pueden crear para cualquier tipo de datos y existen múltiples modelos/métodos que podemos usar para crearlas.
Conclusión
El hecho de que las incrustaciones puedan representar un objeto como un vector denso que contiene su información semántica las hace muy útiles para una amplia gama de aplicaciones de ML.
La búsqueda de similitud es uno de los usos más populares de las incrustaciones de vectores. Los algoritmos de búsqueda como KNN y ANN requieren que calculemos la distancia entre vectores para determinar la similitud. Las incrustaciones de vectores se pueden utilizar para calcular estas distancias. A su vez, la búsqueda del vecino más cercano se puede utilizar para tareas como eliminación de duplicados, recomendaciones, detección de anomalías, búsqueda inversa de imágenes, etc.
