


Apache Kafka es una plataforma para gestionar en tiempo real los datos de tus servicios de forma distribuida, con capacidades impresionantes, pudiendo manejar millones de registros al día. Las tendencias de descentralizar los servicios en tu organización, seguramente te lleven a tener muchos microservicios, que en muchas ocasiones la transmisión de información entre estos puede ser un cuello de botella peligroso para el correcto funcionamiento de tus servicios. Si sabes de que te estoy hablando, estás en el post indicado, necesitas integrar una plataforma de transmisión de datos distribuida como Apache Kafka, te lo presento.
¿Qué es Apache Kafka?
Apache Kafka es un proyecto de intermediación de mensajes open source, desarrollado por la Apache Software Foundation escrito en Java y Scala. El proyecto tiene como objetivo proporcionar una plataforma unificada, de alto rendimiento y de baja latencia para la manipulación de datos en tiempo real, horizontalmente escalable y tolerante a fallos. Puede verse como un gestor de cola de mensajes, con una estructura de publicación-suscripción. Kafka es masivamente escalable, concebida como un registro de transacciones distribuidas.
Aunque Inicialmente fue desarrollado con el objetivo de ser un sistema de cola de mensajes, Kafka para garantizar la legitimidad de los datos, también se abstrajo en un sistema de confirmación de registro de datos. Así que desde que fue creado y abierto por LinkedIn en 2011, Kafka ha evolucionado rápidamente de un sistema cola de mensajes a una plataforma de transmisión de datos en toda regla.
Kafka se utiliza principalmente para crear tuberías de datos en tiempo real y aplicaciones de transmisión de datos. Su éxito está más que garantizado, Kafka se implementa en entornos de producción de miles de compañías como Airbnb, Uber, Brithis Gas, Netflix, Goldman Sachs, LinkedIn, Microsoft, The New York Times, Intuit, Line, Target, entre muchas otras.
¿Qué significa exactamente una plataforma de transmisión de datos distribuida?
Veamos de qué se trata exactamente una plataforma de transmisión de datos distribuida.
Se basa principalmente en 3 funcionalidades clave:
- Permitirte publicar y suscribirte a flujo de datos, similar a una cola de mensajes.
- Sistema de almacenamiento de registros persistente y tolerante a fallos.
- Procesar flujo de datos en tiempo real.
Kafka está diseñado principalmente para 2 tipos de objetivos:
- Construir flujos de datos en tiempo real para obtener datos de forma segura entre sistemas.
- Creación de aplicaciones de transmisión de datos en tiempo real, que pueden transformarse o reaccionar a los flujos de datos.
Para entender cómo Kafka hace toda esta magia, veamos con detalle cómo funciona:
- Para tener la capacidad de mover una gran cantidad de flujo de datos, Kafka trabaja en clúster de uno o más servidores.
- El clúster Kafka almacena flujos de datos ‘records’ en categorías llamadas ‘topics’.
- Cada registro consta de una clave, un valor y una fecha, garantizando así la persistencia de los datos.
Kafka, para permitirte gestionar sus funcionalidades dispone de 4 API’s:
- Producer API, que te permite que una aplicación publique una secuencia de records a uno o más topics de Kafka.
- Consumer API permite que una aplicación se suscriba a uno o más topics y procese la secuencia de records disponibles.
- Streams API permite que una aplicación actúe como un procesador de flujo de datos, consumiendo un flujo de entrada de uno o más topics y produciendo un flujo de salida a uno o más topics de salida, transformando los flujos de entrada en flujos de salida diferentes.
- Connect API permite crear y ejecutar producer o consumer reutilizables que conectan los topics de Kafka a las aplicaciones de tu organización. Por ejemplo, un conector a una base de datos MySQL.

Para que puedas conectar tus servicios de forma sencilla a Kafka, hay disponibles una gran cantidad de librerías para muchos lenguajes de programación.
¿En qué puede ayudarme Apache Kafka?
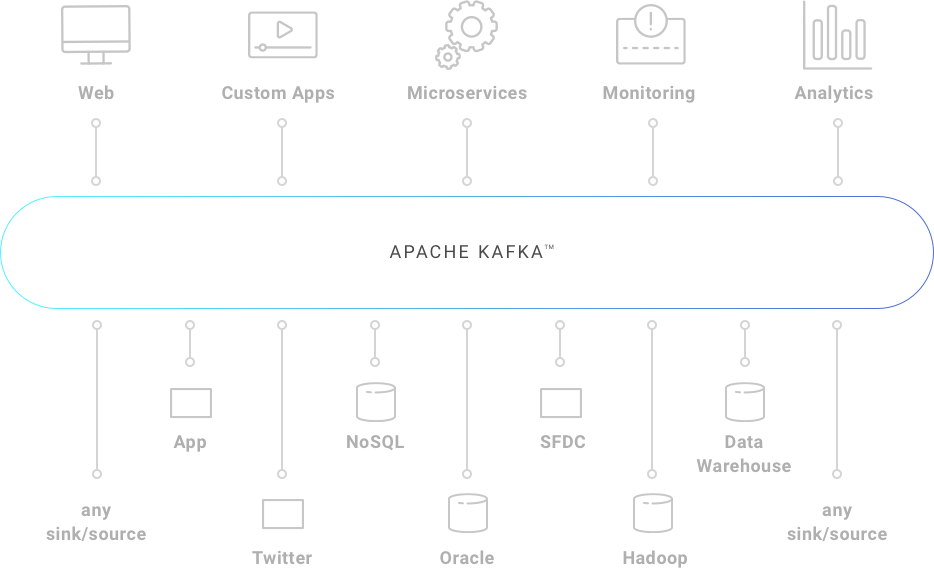
Publicar y suscribirte a flujos de datos
Como hemos comentado, una de sus principales funciones es el inmutable registro de datos, en el que podrás publicar y suscribirte desde cualquier sistema o aplicación en tiempo real. A diferencia de un gestor de cola, Kafka es un sistema distribuido altamente escalable y tolerante a fallos, que permite su implementación en aplicaciones con máxima prioridad de negocio.
Algunas de sus implementaciones es la gestión de pasajeros y conductores en Uber. O como por ejemplo en British Gas, proporcionando análisis en tiempo real y mantenimiento predictivo de toda su infraestructura mediante IoT. El rendimiento único de Kafka, lo hace perfecto para escalar desde una sola aplicación, hasta la implementación como gestor de datos en toda tu infraestructura.
Almacenamiento de datos
Apache Kafka proporciona almacenamiento persistente, permitiéndote distribuir los datos a través de múltiples nodos para una implementación de alta disponibilidad dentro de un solo centro de datos o en múltiples zonas de disponibilidad. Esto puede ser muy útil por ejemplo para guardar registros del tráfico online de tu organización como prueba pericial en caso de un ataque a tu organización.
Procesamiento de datos
La API de Streams de Apache Kafka, dispone de una librería muy potente y ligera, que te permite el procesamiento de datos en tiempo real, lo que le permite agregar, crear parámetros de tiempo, unificar datos dentro de un flujo, entre muchas otras. Un caso muy útil y común es la gestión de análisis de datos en tiempo real para encontrar anomalías en tu lógica de negocio, en el caso de un banco se puede llegar a evaluar fraudes en los ATM.
¿Cómo puedo mejorar el rendimiento de mí API con Apache Kafka?
Con Apache Kafka puedes desacoplar tu API de la lógica de negocio con el objetivo de mejorar el rendimiento. ¿Eing? ¿Desacoplar la API de mi lógica de negocio? Si, supongamos que tus usuarios interactúan con tu API enviando datos a tus servicios. Tu API debe procesar estos datos y almacenarlos en una base de datos, por ejemplo, con el objetivo de realizar algún tipo de cálculo analítico. En este supuesto escenario, tus usuarios no esperarán ningún tipo de respuesta del servidor, únicamente quieren saber que la API ha recibido los datos correctamente.
En este caso, puedes configurar tu API Gateway para que recoja estos datos de tus usuarios, los guarde en un topic de Kafka y que la API Gateway devuelva una respuesta validando que los datos se han recibido y guardado corrrectamente, aunque el microservicio final todavía no haya procesado los datos. De este modo, tus usuarios no esperarán mucho tiempo para el ack. Al no procesar las peticiones directamente con tus microservicios, la interacción de tu API con los usuarios es muy rápida y eficaz.
El microservicio que supuestamente procesa los datos, ira leyendo los mensajes que vienen de Kafka y procesara cada mensaje, uno tras otro. Con este tipo de escenario garantizas la eficiencia de la interacción de tus microservicios con un API Gatweway, desacoplando tu lógica de negocio de la API principal.
Conclusión
Apache Kafka es una herramienta muy poderosa en el procesamiento y transmisión de datos en tiempo real. Facilita mucho la integración en tu organización por la magnífica estructura de su sistema, dividiendo cada una de sus funcionalidades en una API: Producer, Consumer, Streams y Connect.
En resumen, Apache Kafka y sus API’s simplifican la creación de aplicaciones basadas en datos y la gestión de sistemas back-end complejos. En este caso, Kafka garantiza que los datos siempre son tolerantes a fallos, reproducibles y en tiempo real. Ayudándote a construir de forma muy eficaz el tratamiento de los datos que se producen entre tus microservicios, IoT, entre otros, con esta plataforma de transmisión de datos unificada para procesar, almacenar y conectar los datos de tus aplicaciones y servicios en tiempo real.
¿Utilizas Kafka en tu infraestructura? ¿Desacoplas tu lógica de negocio de tu API Gateway? ¡Cuéntanos tu experiencia! Si necesitas soporte con tu proyecto, no dudes en ponerte en contacto con nosotros. Estaremos encantados de ayudarte.
Photo by Tobias Fischer on Unsplash
Referencias:






