


A medida que el Internet de las Cosas (IoT) y otras tecnologías avanzan, la necesidad de procesar y gestionar grandes volúmenes de datos de manera eficiente y en tiempo real se vuelve crucial. Es por ello que quiero compartir contigo qué es la computación en la niebla, sus ventajas, desafíos y su diferenciación respecto a otras tecnologías, así como su aplicación en diversos sectores.
¿Qué es Fog Computing?
La computación en la niebla, fog computing, es una arquitectura que extiende las capacidades de procesamiento y almacenamiento desde los centros de datos centralizados hacia la “niebla”, es decir, nodos ubicados entre la nube y los dispositivos IoT. Estos nodos pueden ser routers, gateways, servidores locales o incluso dispositivos IoT con capacidades de procesamiento. La principal función de estos nodos es realizar tareas de procesamiento local, filtrado de datos y almacenamiento temporal, lo que reduce la cantidad de datos que deben ser enviados a la nube para su procesamiento completo.
Uno de los aspectos más destacados de la computación en la niebla es su capacidad para manejar datos de forma local, lo que resulta en una latencia significativamente menor. Esto es esencial para aplicaciones que requieren tiempos de respuesta inmediatos, como vehículos autónomos, sistemas de tráfico inteligente y monitorización de infraestructuras críticas. En tales casos, incluso un ligero retraso en la transmisión y procesamiento de datos puede tener consecuencias graves, por lo que la capacidad de la “computación en la niebla” para procesar información cerca de la fuente de datos es invaluable.
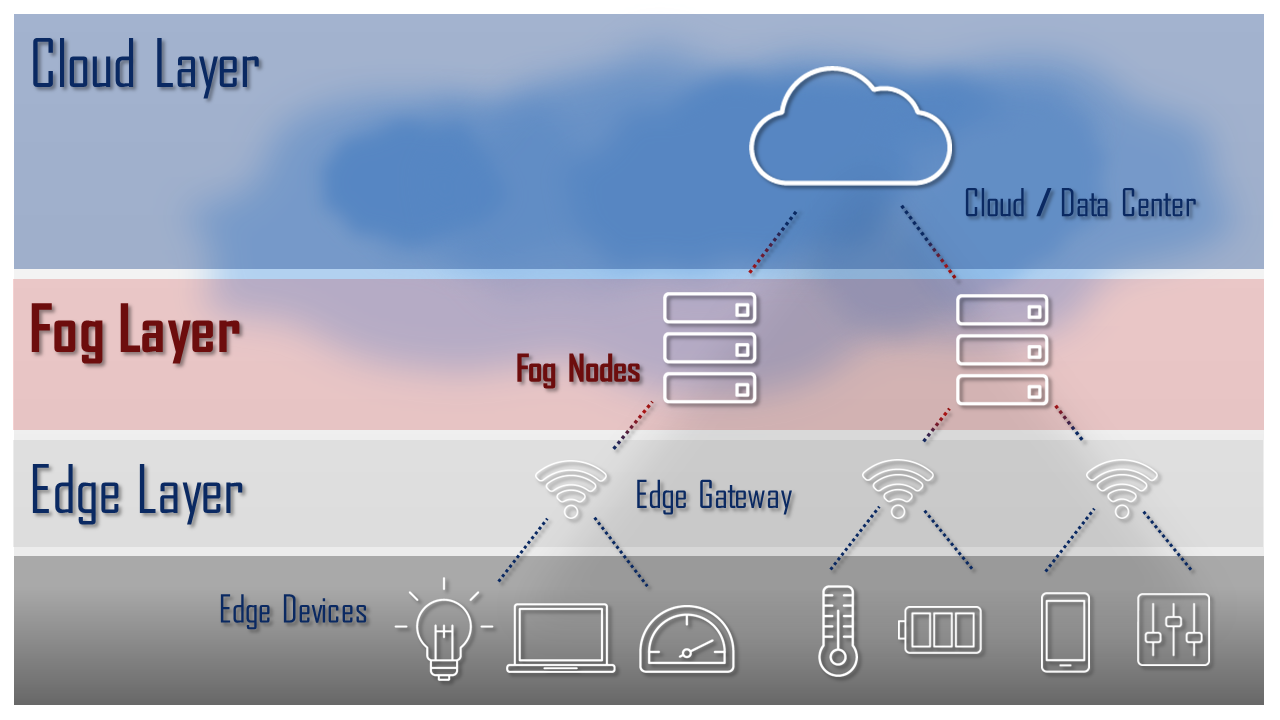
Diferencias entre Fog, Edge y Cloud Computing
Aunque Fog Computing y Edge Computing a menudo se usan de manera intercambiable, existen diferencias claras. El Edge Computing se enfoca en llevar el procesamiento directamente a los dispositivos finales, como sensores. Esto significa que el procesamiento de datos ocurre en el dispositivo que los genera o muy cerca de él. Por el contrario, el Fog Computing agrega una capa intermedia que puede incluir múltiples dispositivos y nodos que se comunican entre sí y con la nube. Esta capa intermedia permite un procesamiento más complejo y una mejor gestión de los datos antes de que estos sean enviados a la nube para análisis adicionales o almacenamiento.
El Cloud Computing, por otro lado, se basa en la centralización de datos y procesamiento en grandes centros de datos remotos. Aunque es altamente escalable y eficiente para ciertos tipos de procesamiento masivo de datos, su dependencia de la conectividad a Internet y la latencia inherente la hacen menos adecuada para aplicaciones que requieren respuestas en tiempo real. La combinación de estos tres enfoques permite una arquitectura más flexible y eficiente, aprovechando las fortalezas de cada uno según la aplicación.
Ventajas de Fog Computing
Fog Computing, ofrece una serie de ventajas significativas que la hacen ideal para una amplia gama de aplicaciones tecnológicas avanzadas. Estas ventajas se derivan principalmente de su capacidad para llevar el procesamiento de datos más cerca del lugar donde se generan, lo que a su vez minimiza la latencia y mejora la eficiencia general del sistema.
- Reducción de la latencia: Una de las principales ventajas de la computación en la niebla es la reducción de la latencia. Al procesar los datos más cerca de su fuente, se minimiza el tiempo de viaje de los datos, lo que permite una respuesta más rápida. Esto es crucial en aplicaciones como la conducción autónoma, donde cada milisegundo cuenta para tomar decisiones críticas.
- Optimización del ancho de banda: Al realizar un preprocesamiento de datos y filtrar la información irrelevante o redundante, la computación en la niebla reduce la cantidad de datos que necesitan ser transmitidos a la nube. Esto no solo ahorra ancho de banda, sino que también reduce los costes asociados con el almacenamiento y procesamiento de datos en el Cloud.
- Mejora en la seguridad y privacidad: La capacidad de procesar datos localmente también mejora la seguridad y privacidad. Al mantener los datos sensibles dentro de la red local o en nodos cercanos, se reduce el riesgo de exposición durante la transmisión a través de redes públicas. Además, permite a las organizaciones cumplir con regulaciones de privacidad de datos más estrictas, como la GDPR en Europa.
- Escalabilidad y flexibilidad: La arquitectura Fog Computing es altamente escalable, lo que permite añadir o eliminar nodos según sea necesario para manejar cargas de trabajo variables. Esto es especialmente útil en situaciones donde la demanda de procesamiento puede cambiar rápidamente, como en eventos deportivos en vivo o emergencias.
Desafíos y desventajas de Fog Computing
A pesar de sus ventajas, la computación en la niebla presenta varios desafíos. La gestión de una infraestructura distribuida es más compleja que la gestión de un centro de datos centralizado. Cada nodo en la niebla debe ser gestionado, mantenido y securizado, lo que puede aumentar los costes operativos y los desafíos técnicos. Además, la seguridad sigue siendo una preocupación importante, ya que cada nodo representa un posible punto de vulnerabilidad. La implementación de medidas de seguridad robustas es esencial para proteger los datos y la infraestructura.
Otro desafío es la interoperabilidad entre dispositivos y nodos de diferentes proveedores. La falta de estándares unificados puede complicar la integración y gestión de una red del Fog Computing. Además, la necesidad de procesar y analizar datos en tiempo real requiere nodos con capacidades de procesamiento avanzadas, lo que puede aumentar los costes de hardware y energía.
Aplicaciones y casos de uso de Fog Computing
La computación en la niebla, Fog Computing, se está aplicando en una variedad de sectores, cada uno aprovechando sus características únicas para mejorar la eficiencia y seguridad. A continuación revisamos algunos de los casos de uso más destacados:
- Ciudades inteligentes: En las ciudades inteligentes, el Fog Computing se utiliza para gestionar y analizar datos de sensores de tráfico, cámaras de seguridad y estaciones meteorológicas. Esto permite una gestión más eficiente del tráfico, una respuesta rápida a emergencias y una mejora general en la calidad de vida de los ciudadanos. Por ejemplo, los sistemas de tráfico inteligentes pueden ajustar los semáforos en tiempo real para optimizar el flujo de tráfico y reducir los tiempos de viaje.
- Salud y telemedicina: En el sector de la salud, Fog Computing facilita la telemedicina y el monitoreo remoto de pacientes. Los dispositivos médicos conectados pueden procesar datos vitales localmente y enviar solo la información crítica a los médicos o centros de datos. Esto no solo reduce la carga en la red, sino que también permite una intervención más rápida en caso de emergencias.
- Industria y producción: En la industria de producción, Fog Computing se utiliza para el mantenimiento predictivo y la optimización de procesos. Los sensores en las máquinas pueden monitorear el rendimiento y detectar signos de desgaste o fallo inminente. Esta información se procesa localmente y se utiliza para programar el mantenimiento antes de que ocurra un fallo, lo que reduce el tiempo de inactividad y los costes de reparación.
- Agricultura: En la agricultura, el Fog Computing se aplica para monitorear y gestionar las condiciones del suelo, el clima y el crecimiento de los cultivos. Los sensores pueden proporcionar datos en tiempo real sobre la humedad del suelo, la temperatura y otros factores críticos, permitiendo a los agricultores tomar decisiones informadas para optimizar el rendimiento de los cultivos y reducir el uso de recursos como el agua y los fertilizantes.
El futuro del Fog Computing
A medida que la tecnología continúa avanzando, es probable que la computación en la niebla, Fog Computing, juegue un papel cada vez más importante en la infraestructura digital global. Con el crecimiento continuo del IoT y la necesidad de procesamiento en tiempo real, la demanda de soluciones de computación en la niebla está destinada a aumentar. Además, con la creciente preocupación por la privacidad y la seguridad de los datos, la capacidad de la niebla para procesar datos localmente se volverá cada vez más valiosa.
La integración de tecnologías emergentes como la inteligencia artificial (IA) y el machine learning (ML) en la computación en la niebla también abrirá nuevas oportunidades. La capacidad de realizar análisis avanzados y tomar decisiones en tiempo real en el borde de la red permitirá aplicaciones más sofisticadas, desde vehículos autónomos hasta redes eléctricas inteligentes. El aprendizaje federado, una técnica que permite entrenar modelos de IA en múltiples dispositivos sin compartir datos brutos, es un ejemplo de cómo la computación en la niebla puede ayudar a preservar la privacidad al tiempo que permite análisis avanzados.
Conclusión
La computación en la niebla es una tecnología esencial para el presente y futuro de la infraestructura digital. Su capacidad para reducir la latencia, optimizar el uso del ancho de banda y mejorar la seguridad de los datos la hace ideal para una amplia gama de aplicaciones, desde ciudades inteligentes, coches autónomos y hasta la gestión de tu salud. Sin embargo, todavía queda superar desafíos significativos en términos de gestión de infraestructura, interoperabilidad y seguridad. Con un enfoque adecuado, la computación en la niebla tiene el potencial de transformar la manera en que procesamos y gestionamos los datos en la era digital.
Referencias:
· https://www.arsys.es/blog/fogcomputing
· https://www.ionos.es/digitalguide/servidores/know-how/fog-computing/
· https://www.computing.es/noticias/fog-computing-la-inteligencia-llevada-al-extremo/
· https://www.thingsmobile.com/es/preguntas-y-respuestas/-que-es-el-fog-computing-
· https://www.itmastersmag.com/glosario/de-la-nube-a-la-niebla-que-es-fog-computing/
